Fast goto definition with low memory footprint

Metals throws away its navigation index when it shuts down. Next time it starts, the index is computed again from scratch. Although this approach is simple, it requires indexing to be fast enough so you don't mind running it again and again. Also, because we don't persist the index to disk, we need to be careful with memory usage.
This post covers how Metals achieves fast source indexing for Scala with a small memory footprint. We describe the problem statement, explain the initial solution and how an optimization delivered a 10x speedup. Finally, we evaluate the result on a real-world project.
The work presented in this post was done as part of my job at the Scala Center.
Problem statement
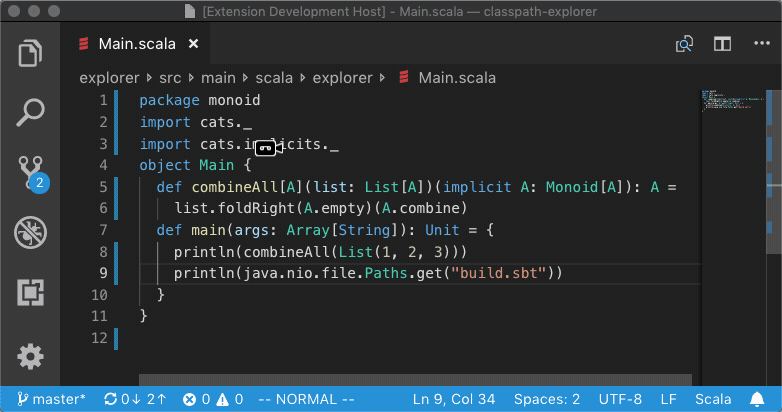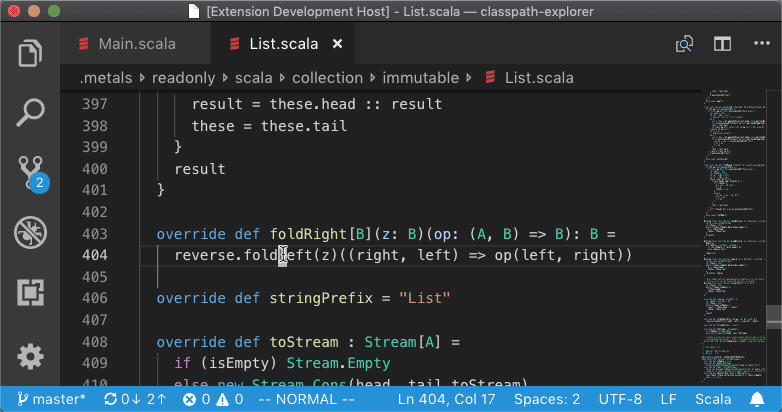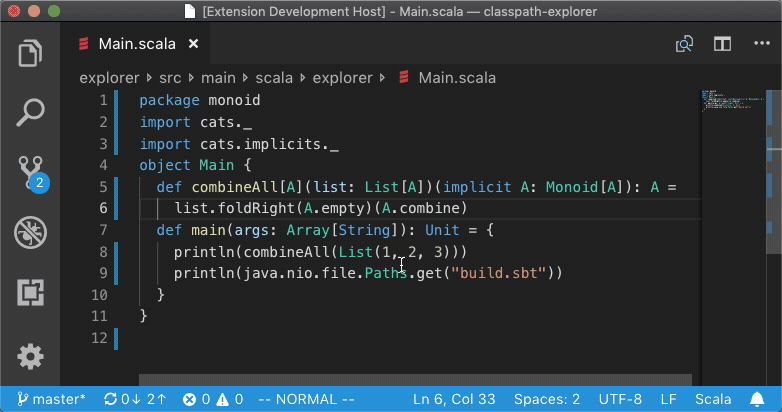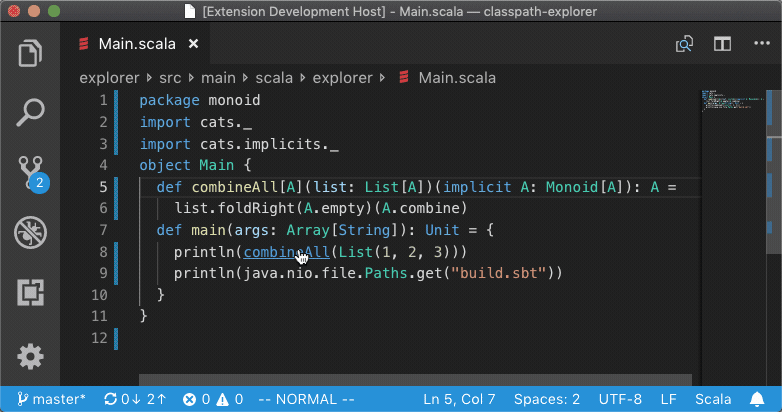
What happens when you run Goto Definition? In reality, a lot goes on but in this
post we're gonna focus on a specific problem: given a method like
scala.Some.isEmpty and many thousand source files with millions of lines of
code, how do we quickly find the source file that defines that method?
There are some hard constraints:
- we must answer quickly, normal requests should respond within 100-200ms.
- memory usage should not exceed 10-100Mb since we also need memory to implement other features and we're sharing the computer with other applications.
- computing an index should not take more than ~10 seconds after importing the build, even for large projects with millions of lines of source code (including dependencies).
To keep things simple, imagine we have all source files available in a directory that we can walk and read.
walk()
// Stream("scala/Option.scala", "scala/Predef.scala", ...)
read("scala/Option.scala")
// "sealed abstract class Option { ... }; class Some extends Option { ... }"
Java
For Java, the challenge is not so difficult since the compiler enforces that each source file contains a single public class with matching filename.
// java/nio/file/Files.java
package java.nio.file;
public class Files {
public static byte[] readAllBytes(path: Path) {
// ...
}
}
To respond to a Goto Definition request for the Files.readAllBytes method, we
- take the enclosing toplevel class
java.nio.file.Files - read the corresponding file
java/nio/File/Files.java - parse
Files.javato find the exact position ofreadAllBytes
This approach is fast (parsing one file is cheap) and it also requires no index (0Mb memory!).
Scala
For Scala, the problem is trickier because the compiler allows multiple toplevel classes in the same source file.
// scala/Option.scala
package scala
sealed abstract class Option[+T] { /* ... */ }
final class Some[+T](value: T) extends Option[T] {
def isEmpty = false
// ...
}
To navigate to the scala.Some.isEmpty method we can't use the same approach as
in Java because the class scala.Some is in scala/Option.scala, not
scala/Some.scala.
One possible solution is to read the scala/Some.class classfile that contains
the filename Option.scala where scala.Some is defined.
$ javap -classpath $(coursier fetch org.scala-lang:scala-library:2.12.8) scala.Some
Compiled from "Option.scala"
...
However, source information in classfiles is not always reliable and it may be removed by tools that process jar files. Let's restrict the problem to only use source files.
Instead of using JVM classfiles, we can walk all Scala source files and build an index that maps toplevel classes to the source file that defines that class. The index looks something like this:
val index = Map[Symbol, Path](
Symbol("scala.Some") -> Path("scala/Option.scala"),
// ...
)
With this index, we find the definition of Some.isEmpty using the same steps
as for Files.readAllBytes in Java:
- take the enclosing toplevel class
scala.Some - query index to know that
scala.Someis defined inscala/Option.scala - parse
scala/Option.scalato find exact position ofisEmptymethod.
The challenge is to efficiently build the index.
Initial solution
One approach to build the index is to use the Scalameta parser to extract the toplevel classes of each source file. This parser does not desugar the original code making it useful for refactoring and code-formatting tools like Scalafix/Scalafmt. I'm also familiar with Scalameta parser API so it was fast to get a working implementation. However, is the parser fast enough to parse millions of lines of code on every server startup?
According to JMH benchmarks, the Scalameta parser handles ~92k lines/second measured against a sizable corpus of Scala code. The benchmarks use the "single-shot" mode of JMH, for which the documentation says:
"This mode is useful to estimate the "cold" performance when you don't want to hide the warmup invocations."
Cold performance is an OK estimate for our use-case since indexing happens during server startup.
The Scala standard library is ~36k lines so at 92k lines/second this solution scales up to a codebase with up to 20-30 similarly-sized library dependencies. If we add more library dependencies, we exceed the 10 second constraint for indexing time. For a codebase with 5 million lines of code, users might have to wait one minute for indexing to complete. We should aim for better.
Optimized solution
We can speed up indexing by writing a custom parser that extracts only the information we need from a source file. For example, the Scalameta parser extracts method implementations that are irrelevant for our indexer. Our indexer needs to know the toplevel classes and nothing more.
The simplified algorithm for this custom parser goes something like this:
- tokenize source file
- on consecutive
package objectkeywords, record package object - on
packagekeyword, record package name - on
classandtraitandobjectkeywords, record toplevel class - on
(and[and{delimiters, skip tokens until we find matching closing delimiter
There are a few more cases to handle, but the implementation ended up being ~200 lines of code that took an afternoon to write and test (less time than it took to write this blog post!).
Benchmarks show that the custom parser is almost 10x faster compared to the initial solution.
[info] Benchmark Mode Cnt Score Error Units
[info] MetalsBench.toplevelParse ss 30 0.349 ± 0.003 s/op
[info] MetalsBench.scalametaParse ss 30 3.370 ± 0.175 s/op
At ~920k lines/second it takes ~6 seconds to index a codebase with 5 million lines of code, a noticeable improvement to the user experience compared to the one minute it took with the previous solution.
Evaluation
Micro-benchmarks are helpful but they don't always reflect user experience. To evaluate how our indexer performs in the real world, we test Metals on the Prisma codebase. Prisma is a server implemented in Scala that replaces traditional ORMs and data access layers with a universal database abstraction.

The project has around 80k lines of Scala code.
$ git clone https://github.com/prisma/prisma.git
$ cd prisma/server
$ loc
Language Files Lines Blank Comment Code
Scala 673 88730 12811 1812 74107
We open VS Code with the Metals extension, enable the server property
-Dmetals.statistics=all and import the build.
$ tail -f .metals/metals.log
time: ran 'sbt bloopInstall' in 1m4s
time: imported workspace in 13s
memory: index using 13.1M (923,085 lines Scala)
We run "Import build" again to get a second measurement.
time: ran 'sbt bloopInstall' in 41s
time: imported workspace in 7s
memory: index using 13.1M (990,144 Scala)
- "ran 'sbt bloopInstall'": the time it takes to dump the sbt build
structure with Bloop, the build server
used by Metals.
- The Prisma build has 44 sbt projects.
- Running
sbttakes 23 seconds to reach the sbt shell.
- "imported workspace": the time it takes to import the build structure into
Metals and index sources of all projects, including the following steps:
- Query Bloop for the dumped build structure, listing all project dependencies, sources and compiler options.
- Walk, read and index all Scala sources in the workspace, happens in both runs.
- Walk, read and index all library dependency sources, happens only for the
first run since the indexer caches
*-sources.jarfile results.
- It's expected that "lines of code" increased by ~70k lines in the second run since we indexed the workspace sources again.
- It's expected that indexing was faster in the second run since indexes are
cached for
*-sources.jarfiles and the JVM has also warmed up.
- "index using 13.1M": the memory footprint of the index mapping toplevel
Scala classes to which file they are defined in.
- Memory is measured using
OpenJDK JOL
GraphLayout.totalSize(). - Note that the server uses more memory in total, this is only for the navigation index.
- The index does not contain entries where the toplevel classname matches the filename, for the same reason we don't index Java sources.
- Memory is measured using
OpenJDK JOL
On average, Goto Definition responds well within our 100ms goal.
time: definition in 0.03s
time: definition in 0.02s
However, occasional definition requests take much longer to respond.
info time: definition in 8s
info time: definition in 0.62s
The outliers happen when navigating inside library dependency sources, which is expected to be slower since we need to type-check those sources before querying the index.
Conclusion
Metals uses a custom Scala parser to index sources at roughly 1 million lines/second in micro-benchmarks. The index is used to quickly respond to Goto Definition requests. On a case-study project containing 44 modules and ~900k lines of Scala sources (including library dependencies), it takes ~10 seconds to import the build structure (including source indexing) and the resulting index uses 13M memory.
The Java+Scala source indexers used by Metals are available in a standalone library called mtags.
libraryDependencies += "org.scalameta" %% "mtags" % "0.3.1"
The mtags library is already being used by the Almond Scala kernel for Jupyter to support Goto Definition inside Jupyter notebooks.
Can the indexer become faster? Sure, I suspect there's still room for 2-3x speedups with further optimizations. However, I'm not convinced it will make a significant improvement to the user experience since we remain bottle-necked by dumping sbt build structure and compiling the sources.
Try out Goto Definition with Metals today using VS Code, Atom, Vim, Sublime Text
or Emacs using the installation instructions here:
https://scalameta.org/metals/docs/editors/overview.html. The indexer is working
when you see "Importing build" in the status bar
