Low-memory symbol indexing with bloom filters

The latest Metals release introduces three new in-memory indexes to implement the features "find symbol references" and "fuzzy symbol search". Indexes are important to provide fast response times for user requests but they come at the price of higher memory usage. To keep memory usage low, Metals uses a data structure called bloom filters that implements space-efficient sets. Thanks to bloom filters, the three new indexes added in the last release use only a few megabytes of memory even for large projects with >500k lines of code.
In this post, we look into how Metals uses bloom filters for fast indexing with small memory footprint. We explain what bloom filters are and how we can encode problems like fuzzy searching to take advantage of the nice properties of bloom filters. Finally, we evaluate these new features on a real-world project: the Akka build.
The work presented in this post was done as part of my job at the Scala Center.
Bloom filters
Bloom filters are a probabilistic
data structure that implements space-efficient sets. The difference between a
bloom filter and a regular set such as HashSet is that bloom filters have the
following limitations:
- the
contains(element)method may return false positives, meaning it can occasionally return true even when the element is not a member of the set. - when creating a bloom filter, you must provide an estimate for how many
elements will be added to the set. A large estimate results in lower false
positive rates for the
contains(element)method at the cost of higher space usage. Conversely, a low estimate results in lower memory usage at the cost of higher false positives for thecontains(element)method. - you can't iterate through the elements of a bloom filter.
In exchange for these limitations, bloom filters are able to compress a large number of elements into a small number of bits. Due to their space-efficiency, bloom filters are used in many applications ranging from browsers, CDNs and cryptocurrencies. In the next sections, we'll explore how bloom filters can also be used in the context of a language server like Metals.
Find symbol references
The "find symbol references" feature shows all usages of a given symbol. For
example, in the demo below we find 843 references to the method Actor.sender()
in the Akka build.

Find symbol references is helpful for users when exploring a codebase and it's also an important component for Metals to implement other features down the road such as "rename symbol".
The challenge when implementing find references is that large projects have many symbol references. Iterating through all symbol references for every source file on every request is too slow. Most symbols appear only in a few source files so we need some way to reduce the search space.
Metals uses bloom filters to reduce the number of files we search when looking for a symbol reference. For every file on disk, we keep an in-memory bloom filter which contains the set of all referenced symbols in that file. When looking for references to a given symbol, we skip files when their accompanying bloom filter does not contain a reference to that symbol. False positive results from the bloom filter are not a problem because they only slow down the response but don't compromise the correctness of the final result.
Concretely, Metals keeps an in-memory map where keys are paths to source files in the workspace.
val references: Map[Path, BloomFilter[Symbol]]
The values represent the set of SemanticDB symbols referenced in that file. A nice property of keying the map by file paths is that we can incrementally update the map as files change. When a file is re-compiled producing a new SemanticDB file, we throw out the old bloom filter and compute a new one from scratch.
To implement the search, we iterate through all entries of the map and only read SemanticDB files from disk when their accompanying bloom filter contains the query symbol (recap: false positives are OK).
val query = // ...
for {
(path, bloom) <- references
if bloom.mightContain(query)
symbolOccurrence <- readSemanticdbOccurrences(path) // read from disk
if isSameSymbol(query, symbolOccurrence)
} yield symbolOccurrence
In the actual Metals implementation, we additionally take care of adjusting positions of the results in case the source file contents have changed since the SemanticDB file was created.
Fuzzy symbol search
The "fuzzy symbol search" feature allows you to navigate to a symbol definition in the workspace sources or library dependencies by typing the symbol's name.

The search is fuzzy, meaning the query doesn't have to be an exact match or a
substring match with the target symbol. For example, we want the query ReaSer
to match the symbol ReactDOMServer. Additionally, all-lowercase queries are
treated as case-insensitive so that searching for nelis matches the symbol
NonEmptyList.
Like with find symbol references, the challenge when implementing fuzzy symbol search is that we have little time to respond and a lot of symbols to search. Testing the search query against every source file the workspace and every entry in the library classpath is too slow.
Metals uses bloom filters to reduce the search space so that we only look at places that are likely to contain matches for the query. We have two different indexes, one for workspace sources and another one for the library classpath.
Workspace sources
The first index is a map keyed by source files in the workspace.
val inWorkspace: Map[Path, BloomFilter[String]]
The values of the map is the set of all possible sub-queries that match symbols defined in that source file. For example, consider the code below.
package data
class NonEmptyListSpec { ... }
object Props { ... }
For this source file, we insert the following sub-queries into the index.
d
da
dat
data
N
No
Non
L
Li
Lis
List
S
Sp
Spe
Spec
NEL
NES
ELS
P
Pr
Pro
Prop
Props
When searching for a query like NoLi, we split the query into the words No
and Li and visit only files whose bloom filter contains all of those exact
sub-queries. We include trigrams of the uppercase characters to further reduce
the search space for queries like NELS that have few lowercase character.
For all-lowercase queries, we return the union of results from multiple
capitalization combinations in order to support case-insensitive searches. For
example, the query neli returns all results matching any of the following
queries.
neli
Neli
NEli
NeLi
NelI
NELi
NElI
NeLI
NELI
To implement the search, we iterate through all entries of the in-memory map and only visit the source files on disk whose bloom filter contain a match for the query.
val query = ...
for {
(file, bloom) <- inWorkspace
if bloom.mightContain(query)
symbol <- parseSymbols(file) // reads from disk
if isFuzzyMatch(query, symbol)
} yield symbol
Like with find symbol references, false positive results from the bloom filter slow down the response but don't compromise the correctness of the result. Also, we incrementally update the map as files in the workspace change by removing old entries and compute a new bloom filter for the updated source file.
Library classpath
The library classpath index is similar to the workspace sources index except the
keys of the map are package symbols (example scala/collection/) instead of
file paths.
val inClasspath: Map[Symbol, (BloomFilter[String], Seq[Symbol])]
Unlike the workspace sources index, the library classpath index does not need to be incrementally updated when files re-compile. The bloom filters in the values of the map use the same sub-query technique as the bloom filters in the workspace sources index. For each bloom filter, we additionally store a listing of all members of that package. If a query matches a given bloom filter, we test the fuzzy search against all members of the package.
val query = ...
for {
(pkg, (bloom, packageMembers)) <- inClasspath
if bloom.mightContain(query)
member <- packageMembers
if isFuzzyMatch(query, symbol(pkg, member))
definitionOnDisk <- findDefinition(member) // writes to disk
} yield definitionOnDisk
Due to how the Language Server Protocol works, the findDefinition method
writes sources of library dependencies to disk so the editor can find the symbol
definition location. To reduce the number of files written to disk, Metals
limits the number of non-exact search results from the library classpath index.
In the actual Metals implementation, the listing of package members is GZIP compressed to reduce memory usage and the members are decompressed on-demand when a bloom filter matches the query.
Evaluation
We test Metals on the Akka codebase to evaluate the performance of our bloom filter indexes. Akka is a library to build highly concurrent, distributed, and resilient message-driven applications on the JVM.

The Akka codebase has 300-600k lines of code depending on whether you include comments and/or Java sources. Metals indexes both Java and Scala sources for fuzzy symbol search but only Scala sources for find symbol references.
$ git clone https://github.com/akka/akka.git
$ cd akka
$ loc
Language Files Lines Blank Comment Code
Scala 1,951 358,149 57,528 76,605 224,016
Java 486 250,609 19,838 51,291 179,480
We open the base directory with Visual Studio Code and update the "Metals Server
Properties" setting to -Dmetals.statistics=all to enable additional
logging output. We import the build, open the file Actor.scala and wait until
compilation has finished. It is normal if this step takes several minutes to
complete.
Response times
First, we measure the response times for find symbol references.
time: found 8 references to symbol 'akka/actor/ActorCell.contextStack.' in 8ms
time: found 11 references to symbol 'akka/actor/Actor#postRestart().' in 17ms
time: found 146 references to symbol 'akka/actor/PoisonPill.' in 0.16s
time: found 163 references to symbol 'scala/collection/IterableLike#head().' in 0.23s
time: found 1027 references to symbol 'akka/actor/Actor#' in 0.5s
time: found 816 references to symbol 'scala/package.Throwable#' in 0.63s
time: found 6103 references to symbol 'scala/Predef.String#' in 1.54s
Response times range from 8ms up to 1.6s depending on the number of results. The
6103 references to String origin from 913 source files, which is almost half
of all Scala source files in the repository. These numbers do not take into
account the delay in the editor to display the results in the UI. For large
results like String, this delay can be several seconds depending on the
editor.
Next, we measure the response times for fuzzy symbol search.
time: found 0 results for query 'ConfigSEr' in 13ms
time: found 10 results for query 'ConfigSer' in 0.1s
time: found 105 results for query 'ActorRef' in 0.21s
time: found 105 results for query 'actorref' in 0.31s
time: found 1002 results for query 'actor' in 0.54s
time: found 3974 results for query 'S' in 1.98s
Response times range from 13ms up to 2s depending on the query and number of
results. Queries with typos like ConfigSEr have 0 results and respond
instantly, while generic queries like S have ~4k results and take 2 seconds to
respond. Observe that all-lowercase queries like actorref are slower than
capitalized queries like ActorRef, which is expected because we test multiple
capitalization combinations for case-insensitive searches.
Memory usage
Next, we look at the memory usage of the bloom filter indexes. The numbers are
computed with JOL
GraphLayout and the element counts are approximate number of insertions into
the bloom filters.
memory: references index using 3.72M (274,747 elements)
memory: workspace symbol index using 1.89M (173,419 elements)
memory: classpath symbol index using 1.72M (382,243 elements)
The three bloom filter indexes use 8Mb combined for the entire Akka build. The 8Mb include the maps with file/symbol keys and also a GZIP compressed listing of package members for the classpath symbol index. For comparison, the goto definition index that does not use bloom filters requires 16Mb alone.
memory: definition index using 15.9M (337,532 lines Scala)
Indexing time
Next, we look at the time it takes to construct the indexes after build import.
time: imported build in 2.41s
time: updated build targets in 0.12s
time: started file watcher in 4.36s
time: indexed library classpath in 0.8s
time: indexed workspace SemanticDBs in 2.18s
time: indexed workspace sources in 3.35s
time: indexed library sources in 1.59s
The Akka build contains many source files but few library dependencies. The
bottle-neck appears to be starting the file watcher and parsing all *.scala
and *.java sources in the workspace. The following flamegraph shows a detailed
breakdown of what goes on during indexing.
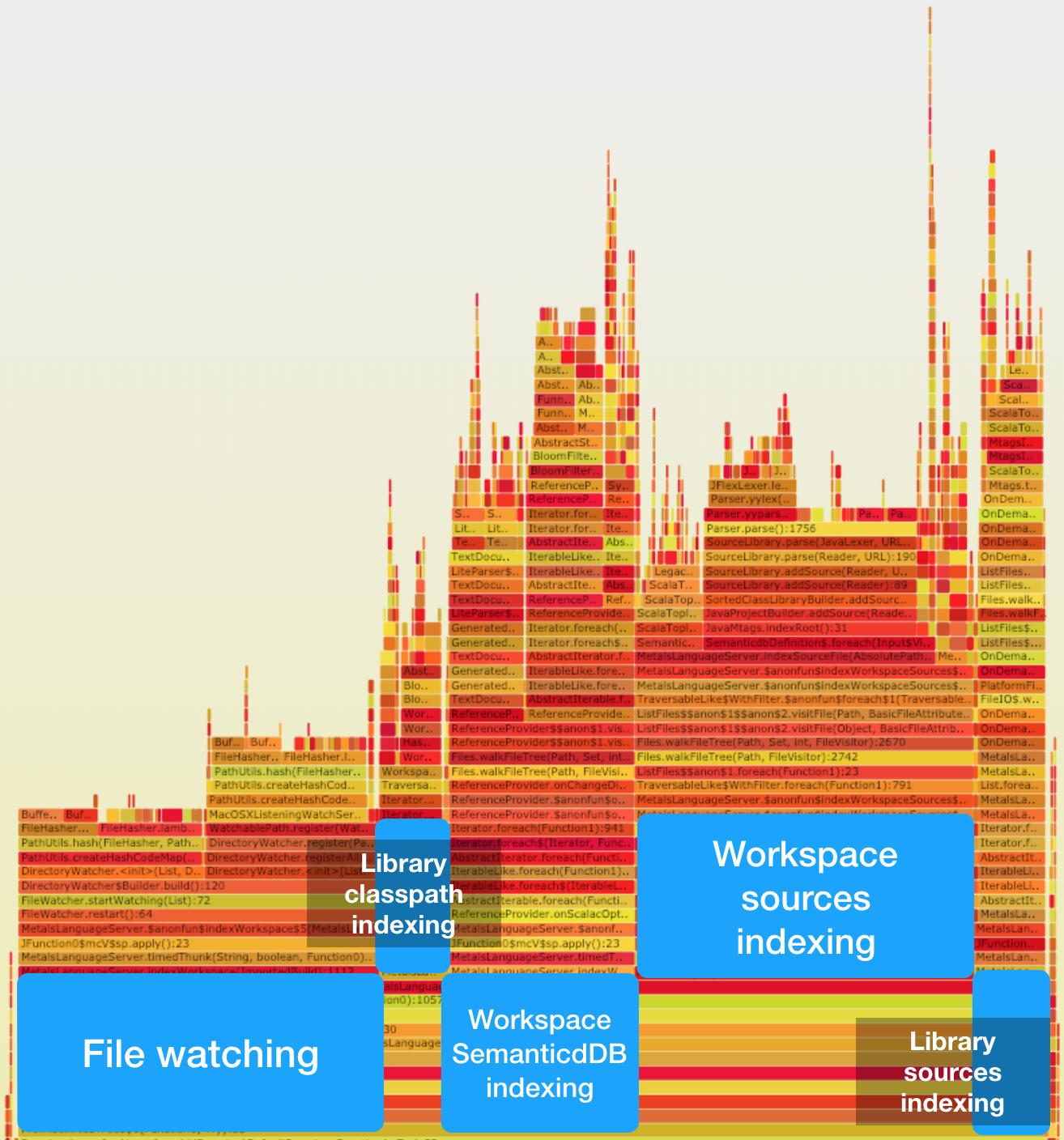 (https://geirsson.com/assets/metals-akka-initialize.svg)
(https://geirsson.com/assets/metals-akka-initialize.svg)
Click on image to interactively explore the flamegraph.
Some observations:
- it's slower to start the file watcher than compute all three indexes for find symbol references and fuzzy symbol search, combined.
- the method
BloomFilter.put()accounts for 2.26% of the total runtime.
For comparison, below is another flamegraph for the same indexing pipeline but in a different project, Prisma. The total indexing time is around 8 seconds on a cold server for both Akka and Prisma but the distribution is different for how long each indexing task takes. Prisma has fewer sources (80k lines of Scala code, no Java) and a larger number of library dependencies compared to Akka.
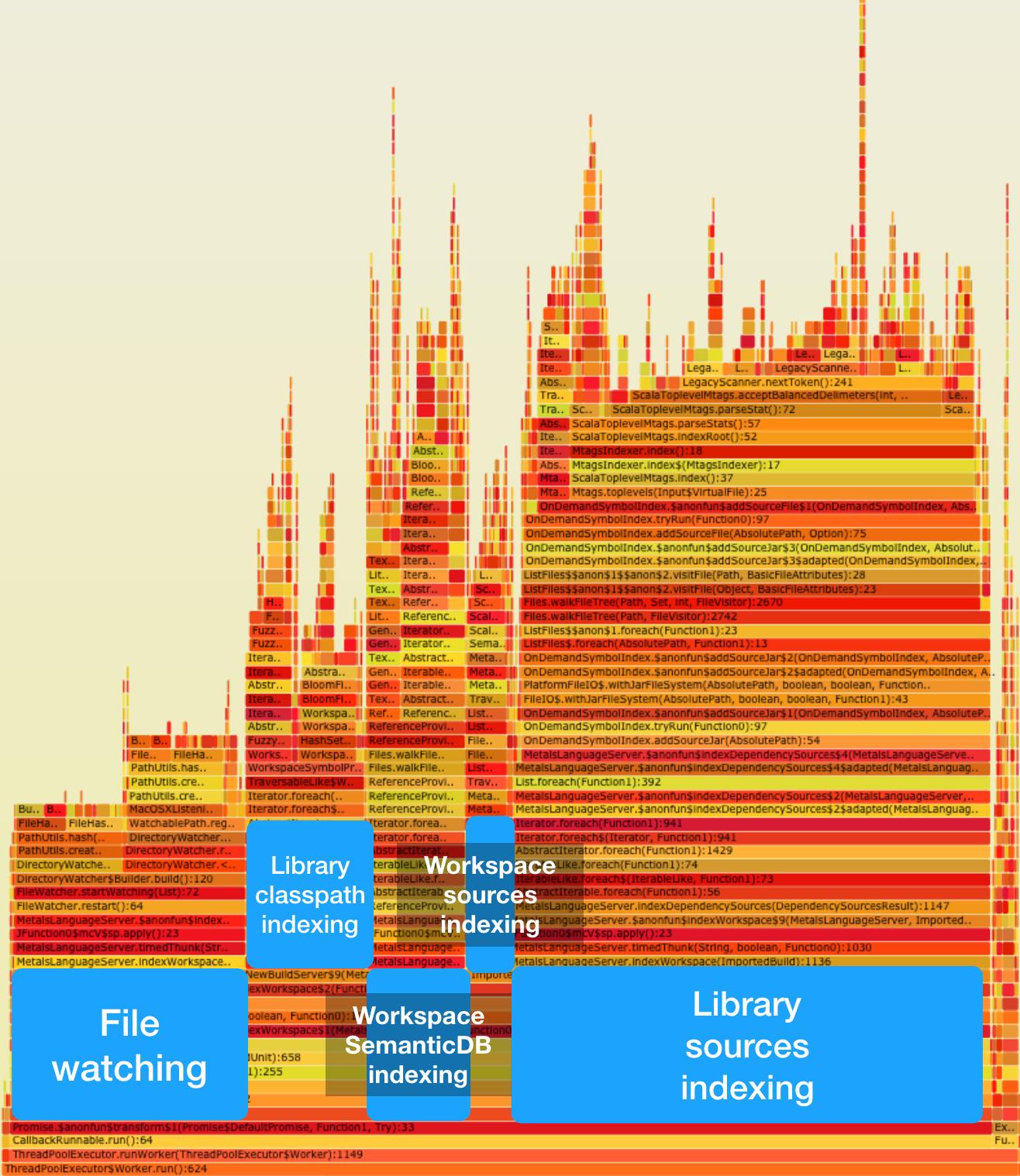 (https://geirsson.com/assets/metals-prisma-initialize.svg)
(https://geirsson.com/assets/metals-prisma-initialize.svg)
Click on image to interactively explore the flamegraph.
Computing the bloom filter indexes for find symbol references and fuzzy symbol search takes proportionally even less time in Prisma compared to Akka. The Prisma project is a good representation for projects with less than 100k lines of code and a large number of library dependencies.
Conclusion
Metals uses three bloom filter indexes to implement the features "find symbol
references" and "fuzzy symbol search". On a case study project containing 600k
lines of code, all three indexes use 8Mb of memory combined and enable
sub-second response times for most user requests. Response times for fuzzy
symbol search is occasionally slower for short queries like S but this
limitation is not inherent with the bloom filter indexing approach and may be
addressed in future releases.
Computing the bloom filter indexes takes 4s in our case-study project, out of total 16s for the combined "import build" and "indexing" steps. These steps run whenever Metals starts in an existing project or after the build changes. Can indexing be made faster? Probably yes, but the user experience will still remain bottle-necked by sbt build export and compilation of workspace sources, which frequently take many minutes to complete on large projects.
The indexes are in-memory maps where the keys are file paths and values are bloom filters. When files change, we can incrementally update the indexes by computing a new bloom filter for the updated source file.
The bloom filter indexes are only used to narrow down the search space by eliminating files and packages that don't contain relevant results for the user query. False positive results slow down response times but don't compromise the correctness of the final result.
Try out Metals today with VS Code, Atom, Vim, Sublime Text or Emacs using the installation instructions here https://scalameta.org/metals/docs/editors/overview.html.
The indexer is working when the status bar says Indexing⠋
